

noteのデータ基盤アーキテクチャを紹介 - レイクハウスによるシンプル構成で誰でも使いやすいデータ基盤へ

note株式会社では、全社員のデータ活用が活発になってきており、データ基盤も進化を続けています。
Snowflakeへの全面移行によるコスト削減やデータ収集と処理の効率化などを行ってきたことで、シンプルな構成を保ちつつ使いやすいデータ基盤になってきました。しかし、まだまだ課題も山積みの状態です。
今回の記事では、データ基盤開発のリーダーである久保田 勇喜に、noteのデータ基盤のアーキテクチャの解説と現状の課題について詳しくお聞きしました。
※ 記事の最終更新:2024年6月
久保田 勇喜 / データ基盤チームリーダー
2015年、株式会社Adwaysに入社。アプリの事前予約システムの開発などを担当。2017年からBulbit株式会社(現UNICORN株式会社)でDSPの開発に着手。2021年からnote株式会社に入社し、データエンジニアとしてデータ基盤の開発・運用に携わる。現在はデータ基盤チームのリーダーとして、開発から及びデータ活用の推進を担当。
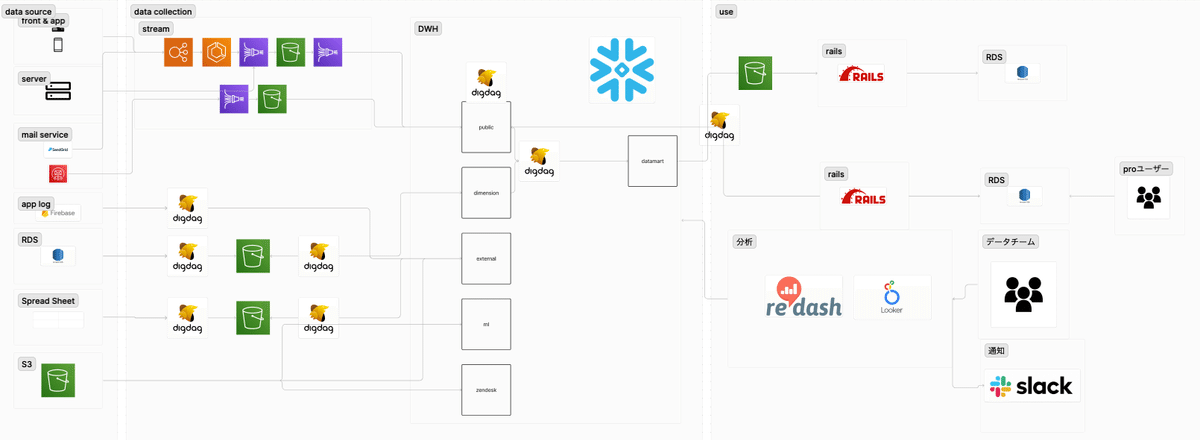
全体のアーキテクチャ紹介 - Snowflakeを中心としたレイクハウス構成
データ基盤チームリーダーの久保田です。
noteのデータ基盤では、取り扱うデータをすべてSnowflakeに入れています。Snowflake導入以前はデータの所在がバラバラになっていて、データの活用に課題がありました。しかし、現在はSnowflakeに集約されたことで、Snowflake中心のアーキテクチャに変わっています。
リバースELTを導入しているため、Railsなどのサーバーサイドからもデータ活用が可能な状態になっています。分析だけではなく、機能開発にもデータ活用が広がっています。
また、データをSnowflakeに集約することで、ETLに使用していたAWSのGlueなどをSnowparkに変更することができ、年単位のコストが500〜600万円ほど削減することができました。
2年ほどSnowflakeで運用しているのですが、移行してよかったなと感じています。以前はデータの集計が遅くて分析ができないこともありましたが、今は様々な場面でデータ基盤が利用されるようになりました。
シンプルさを保ちつつトレンドを追うアーキテクチャ

データ基盤は色々なチームから多種多様な依頼が来ます。また、データ基盤自体も色々なチームの人が利用します。そのため、シンプルな構成を保つことが重要だと考えています。
最近のデータ周りのトレンドとしては、データウェアハウスとデータレイクの両方の機能やアーキテクチャを統合したレイクハウスがあります。以前はデータウェアハウスとデータレイクが分かれていましたが、ストレージの料金が安くなり、ウェアハウスの性能が向上したことで一緒になったのがレイクハウスです。今のアーキテクチャはここも意識し、シンプルさを保ちつつ、トレンドも追うようにしています。

サーバサイドやフロントエンドなどのリアルタイムなログデータは、AWS Firehoseを使ってSnowflakeに流しています。
以前はS3にデータを置いて、Athenaでそのまま使っていることやETLしたデータを置いていることもありましたが、現在ではS3はログデータをSnowflakeに同期する前の、一時的な置き場所として使用しています。
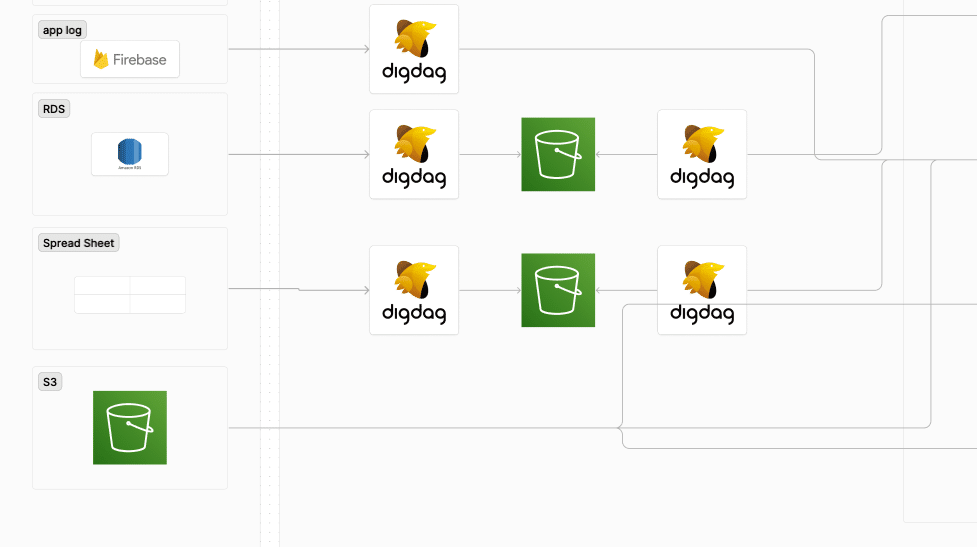
バッチなどによる定期的なデータの取り込みには、ワークフローエンジンであるDigdagを利用しています。定期的にデータをSnowflakeに送る部分やETLの処理の実行などを行っています。
課題と今後の展望
利用者が増えたことによるコストの増加
Snowflakeを中心としたアーキテクチャに変更したことで、構成はシンプルになり、コストカットも成功しました。
しかし、全体として見るとデータの活用者が増えたことでRedashやLookerを使う人も増え、コストが再び増加している面もあります。開発以外の人もデータを使用するようになり、会社全体がデータドリブンになってきているのは良い傾向ですが、その影響で料金のコントロールが難しくなっています。

理想としてはデータ分析はLookerに統一したいです。Redash上で違う人が同じようなダッシュボードを作ったり、微妙にクエリの書き方が違ったり、集計の結果に差分が出てしまったり……と、データ分析の精度に課題があります。そのため、現在RedashのダッシュボードをLookerに移行中です。
データの使いやすさの向上
Redashなどのダッシュボード問題などが起こる背景として、個人のSQLの知識だけではなく、データの見つけやすさ自体に課題があると感じています。
データが増えていき、利用シーンも多岐にわたることで、中間テーブルが増え、ダッシュボードが増加して来ると、欲しい情報がどこにあるのかがわからなくなり、分析チームやデータエンジニアに問い合わせが多発してしまいます。問い合わせが多発することで、分析チームやデータエンジニアのリソースが逼迫してしまうでしょう。
そこで、データ基盤チームで、@datainfra-aiというボットを作り、問い合わせに対する回答を自動化する仕組みを新たに導入しました。
まだまだ試験段階ですが、今後機能や性能を上げていき、問い合わせに対するリソースを50%ほど軽減することが目標です。
まとめ
データ活用は広まりましたが、まだまだ改善の余地があります。バッチ処理やデータ同期の改善も検討中です。Digdagを使い続けるのか検討したり、RDSからSnowflakeまでの同期時間の短縮を目指してたりしていますが、アーキテクチャはシンプルな構成を維持しながら進めるように気をつけています。
データの使いやすさを向上させることで、誰でも簡単にデータにアクセスできる環境を目指していきます。
※ この記事は、インタビュー内容をもとにライターが再編集しました
▼noteの技術記事がもっと読みたい方はこちら